GPT-5.5·오퍼스 4.7 성능 저하, OpenAI·앤트로픽 양사 결국 시인

출시 한 달 만에 GPT-5.5와 오퍼스 4.7 모두에서 성능 저하 불만이 폭발했고, 두 회사 모두 결국 인정했다. 앤트로픽은 4월 23일 정식 포스트모템에서 'tool call 사이 ≤25 단어' 시스템 프롬프트가 오퍼스 4.7 코딩을 망쳤다고 자백했고, OpenAI Codex 책임자 Thibault Sottiaux는 5월 15일 트윗 한 줄로 GPT-5.5의 두 가지 결함을 시인한 뒤 다음 날 fix 완료를 발표했다.
OpenAI의 GPT-5.5와 앤트로픽의 오퍼스 4.7. 2026년 4–5월 동안 인공지능 모델 양대 산맥의 최신 플래그십이 모두 출시 한 달 만에 '성능이 떨어졌다'는 사용자 불만 폭주에 동시에 휩싸였다. 그리고 두 회사 모두 끝내 인정했다. 한쪽은 정식 포스트모템으로, 한쪽은 트윗 한 줄로.
앤트로픽은 4월 23일 'An update on recent Claude Code quality reports'라는 자체 포스트모템을 공개했고, OpenAI Codex 책임자 Thibault Sottiaux는 5월 15일 X에서 GPT-5.5 성능 저하를 공개 시인했다. 형식은 달라도 메시지는 같다 — '문제가 있었고, 우리가 만든 거다.'
출시 한 달, 같은 시기에 터진 같은 불만
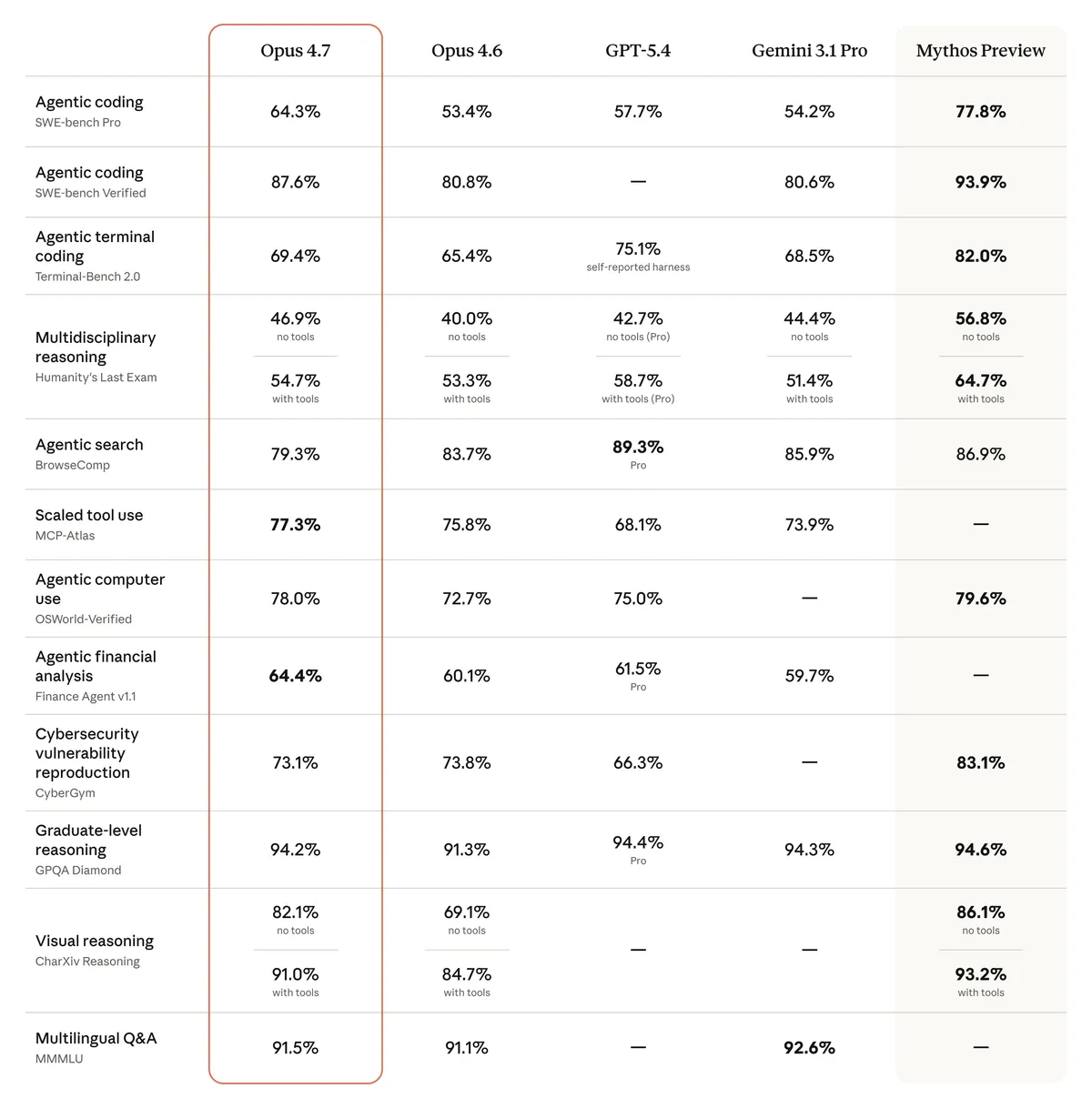
앤트로픽은 4월 16일 오퍼스 4.7을 일반 공개했다. SWE-bench Pro 64.3%, 라쿠텐 SWE-Bench 기준 4.6 대비 코딩 +13%, 시각 인식 정밀도 98.5% 같은 숫자가 발표문을 채웠다. OpenAI는 약 일주일 뒤인 4월 23일 GPT-5.5를 공개했고, 5월 5일 'GPT-5.5 Instant'를 ChatGPT의 기본 모델로 전환했다.
그런데 양사 모두 출시 한 달이 채 지나기 전부터 같은 종류의 불만이 쌓이기 시작했다. Reddit의 r/ClaudeAI에서는 '오퍼스 4.7이 4.6보다 답이 장황하고 집중력이 흐트러진다'는 글이 늘었고, r/codex와 r/ChatGPTcomplaints에서는 GPT-5.5의 추론 속도가 느려지고 맥락 압축이 깨졌다는 보고가 누적됐다. 한 달 전 GPT-5.4 벤치마크 컨트로버시 기사에서 다뤘던 패턴 — 출시 직후의 호평과 며칠 뒤의 현실 체감 사이의 간격 — 이 다시 반복된 셈이다.
앤트로픽의 자백: '도구 호출 사이 25단어'가 모든 걸 망쳤다

앤트로픽 엔지니어링 블로그가 4월 23일 공개한 포스트모템은 솔직하다. Claude Code 품질 저하 보고는 사용자 착시가 아니라 '세 가지 별도 변경이 결합해 광범위한 성능 저하처럼 보였다'고 명시했다.
첫째, 3월 4일 기본 추론 강도를 high에서 medium으로 낮춘 변경 — 사용자가 속도보다 똑똑함을 원했다는 이유로 4월 7일 되돌렸다. 둘째, 3월 26일 도입한 프롬프트 캐싱 최적화가 한동안 쉰 세션 이후 직전 사고 내역을 한 번이 아니라 매 턴마다 지우는 버그였다 — 4월 10일 수정. 셋째는 앤트로픽 포스트모템에서 가장 강조된, 오퍼스 4.7 전용 이슈다. 출시일인 4월 16일에 들어간 답변 길이 축소 시스템 프롬프트가 '도구 호출 사이 텍스트를 25단어 이하로 유지하라'고 모델에게 지시했고, 이게 코딩 품질을 깎아먹고 있었다. 4월 20일 되돌렸고 4월 23일 전 가입자 사용량 한도를 초기화했다.
앤트로픽은 'API와 추론 레이어는 영향을 받지 않았다'와 '모델을 의도적으로 떨어뜨리는 일은 없다'라는 두 문장을 거듭 강조했고, 향후 시스템 프롬프트 변경에 관찰 기간과 단계적 배포를 적용하겠다고 약속했다. 시스템 프롬프트 버그가 플래그십을 망친 사례치고는 드물게 투명한 자료다.
OpenAI의 시인: Sottiaux의 트윗 한 줄로 끝난 24시간

OpenAI는 형식이 달랐다. 5월 8일 GPT-5.5 모델의 오류율 증가가 OpenAI 상태 페이지에 약 1시간 43분짜리 인시던트로 등재된 적은 있지만, 본격적인 사용자 불만 폭주는 5월 중순이었다. 5월 15일, Codex 책임자 Thibault Sottiaux가 트윗으로 '코덱스 팀은 일부 사용자에게서 GPT-5.5 성능이 떨어졌다는 보고를 인지하고 조사 중'이라고 적었다.
다음 날 새벽, 같은 계정에서 더 단호한 글이 올라왔다. '지난 약 48시간 동안 코덱스에서 GPT-5.5의 성능 저하를 설명할 수 있는 두 가지 이슈를 발견해 수정했다. 오늘 저녁 사용량 한도를 초기화하겠다.' 이 글은 좋아요 6,374·리트윗 445·조회수 82만을 기록했다. 6시간 뒤 '안정 복구를 확인했다'는 짧은 후속까지 더해져, OpenAI Codex 인정·수정·종결이 24시간 안에 끝났다.
다만 정식 포스트모템은 나오지 않았다. 어떤 두 이슈였는지, 인프라 문제인지 라우팅 문제인지 프롬프트 변경 때문인지에 대한 구체적 설명도 없다. 앤트로픽의 4월 23일 자료와 비교하면 같은 종류의 사건을 다루는 방식의 차이가 또렷하다. 앞으로 사용자 신뢰 관점에서는 이번 OpenAI Codex 인정이 빠른 대응 사례로 평가될지, 문서 없는 미봉책으로 기억될지가 갈릴 지점이다.
양사가 한목소리로 부인하는 한 가지 — '추론 레이어는 멀쩡하다'
앤트로픽은 포스트모템에서 'API와 추론 레이어는 영향을 받지 않았다'고 명시했고, Sottiaux도 트윗에서 코덱스 환경에 한정된다는 점을 분명히 했다. 즉 두 회사 모두 '모델 자체나 추론 인프라가 깨진 게 아니라, 그 위에 얹은 프로덕트 레이어가 문제였다'는 같은 톤으로 정리한다.
그러나 앤트로픽 상태 페이지를 들여다보면 결이 다른 데이터가 보인다. 4월 16일 정식 공개 이후 약 한 달간 '클로드 오퍼스 4.7 오류율 증가' 인시던트가 5월 4·7·8·14일에 반복 등재됐고, 5월 15일에는 여러 모델에 걸친 오류율 증가 인시던트가 또 한 번 잡혔다. API 레이어가 '영향 없음'이었다고 해도, 사용자 체감에는 프로덕트 버그와 API 인시던트가 합쳐져 AI 모델 회귀로 받아들여졌다. 한 번 박힌 AI 모델 회귀 인식은 트윗 한 줄로 지워지지 않으며, AI 모델 회귀를 부정할수록 사용자는 더 의심한다.
수정이 끝난 뒤에도 사라지지 않는 '너프된 느낌'
앤트로픽이 4월 20일 답변 길이 축소 프롬프트를 되돌리고 OpenAI가 5월 16일 GPT-5.5 두 이슈를 수정한 뒤에도, X·Reddit의 오퍼스 4.7 너프 분위기는 가시지 않았고, 오퍼스 4.7 너프 의혹은 새로운 트윗으로 매일 다시 떠올랐다. 5월 12일자 한 트윗은 '4.7이 알 수 없는 방식으로 너프됐고, 차라리 GPT-5.5가 옛날 4.6처럼 느껴진다'며 1,582 조회수를 모았고, 또 다른 트윗은 '40초를 기다려서 더 못한 답을 받는다'며 408 조회를 기록했다.
체감 저하가 데이터로 잡히는 사례도 나왔다. 한 연구자는 사이버보안 챌린지 셋(Cybench)에 오퍼스 4.7을 돌려, 40개 챌린지 중 11개에서 모델이 풀이를 거의 그대로 외워서 재생한다는 '훈련 데이터 오염' 패턴을 공개했다. 모델 자체 품질에 대한 의심은 프로덕트 계층 버그가 해결된 뒤에도 살아남은 셈이다.
이 흐름은 한 달 전 Gemini 3.1·GPT-5.4 의도적 성능 저하 의혹에서 봤던 그림과 닮아 있다. 회사가 'API는 정상'이라고 말해도, 사용자가 매일 쓰는 ChatGPT·Claude Code 화면이 안 좋아 보이면 그게 '진짜 성능'이 된다. 결국 오퍼스 4.7 너프 논란이 잦아드는 시점은 fix 발표일이 아니라 다음 모델이 나오기 전까지의 누적 체감이 결정한다.
AI 모델의 진짜 평가는 출시 한 달 뒤에 정해진다
출시일 벤치마크는 마케팅에 충분하지만, 사용자 신뢰는 운영에서 만들어진다. 앤트로픽의 4월 23일 자료는 그 점에서 모범 사례에 가깝고, OpenAI의 24시간짜리 트윗 시인은 빠른 대응의 모범인 동시에 문서화 부재라는 빈자리를 남겼다.
지금 사용자가 GPT-5.5와 오퍼스 4.7에 가지는 의심은 모델 한 줄이 아니다. 일정 압박 속에서 시스템 프롬프트가 검토 없이 들어가고, 캐시 최적화가 조용히 동작 방식을 바꾸고, 상태 페이지의 인시던트가 '영향 없음' 주장과 공존하는 — 운영 전체에 대한 의심이다. 다음 플래그십이 4.8이든 GPT-5.6이든, 신뢰는 다시 출시일이 아니라 출시 한 달 뒤에 결정될 것이다.




- Anthropic Engineering - An update on recent Claude Code quality reports
- Thibault Sottiaux (X) - We found and fixed two issues that could explain this degradation of the capability of GPT-5.5 in Codex
- Anthropic Status - Elevated errors on Claude Opus 4.7 — May 2026 incident history
- OpenAI Status - Increased Error Rate for gpt-5.5 (May 8, 2026 incident)
- Anthropic - Introducing Claude Opus 4.7