엔비디아, 200억 달러짜리 추론 칩 Groq 3 LPU 공개하다
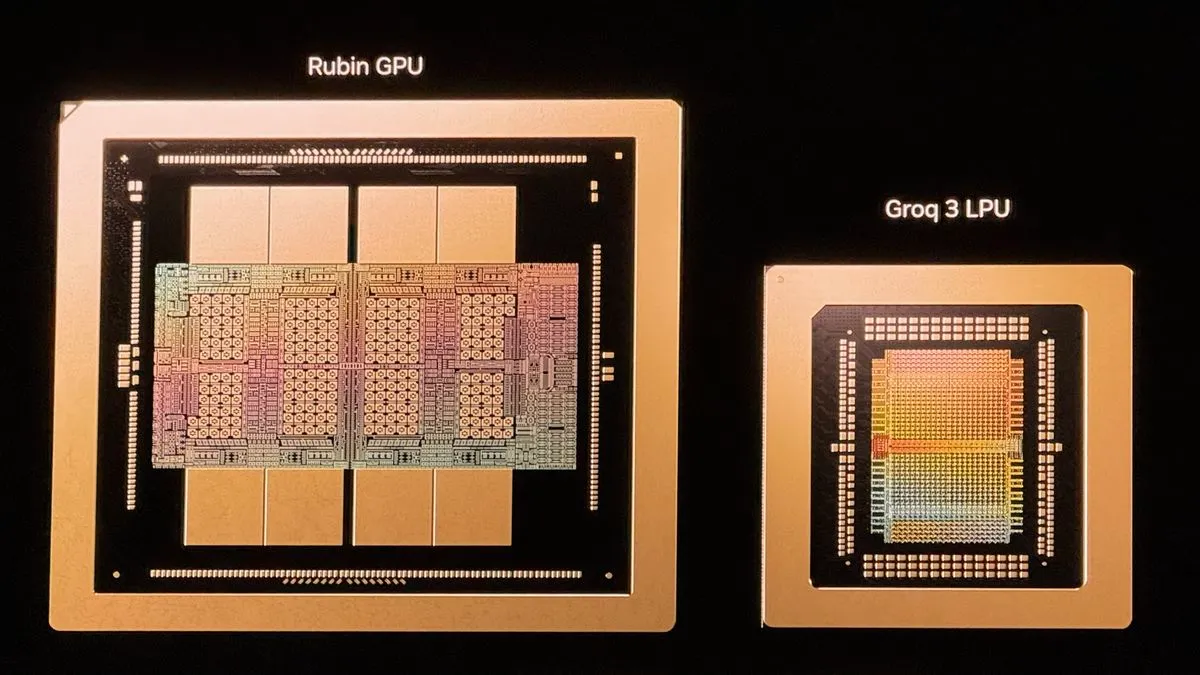
엔비디아가 200억 달러에 인수한 그록의 추론 전용 칩 Groq 3 LPU가 GTC 2026에서 공개됐다. SRAM 기반으로 GPU 대비 7배 대역폭, 35배 전력 효율을 달성한 이 칩은 GPU는 학습, LPU는 추론이라는 AI 컴퓨팅 이원화 시대의 개막을 알린다.
2025년 12월, 엔비디아가 추론 전용 칩 스타트업 그록를 200억 달러에 인수했다. 2019년 네트워킹 기업 멜라녹스를 69억 달러에 사들였을 때, 업계는 의아해했다. 하지만 멜라녹스 기술은 데이터센터 연결의 핵심이 되어 엔비디아의 AI 지배력을 완성하는 마지막 퍼즐이 됐다. 젠슨 황이 이번 인수를 '멜라녹스 모먼트'라고 부른 이유가 여기에 있다. 그리고 GTC 2026 키노트에서 그 결과물, Groq 3 LPU가 처음으로 세상에 모습을 드러냈다.
SRAM이 HBM을 대체한다면

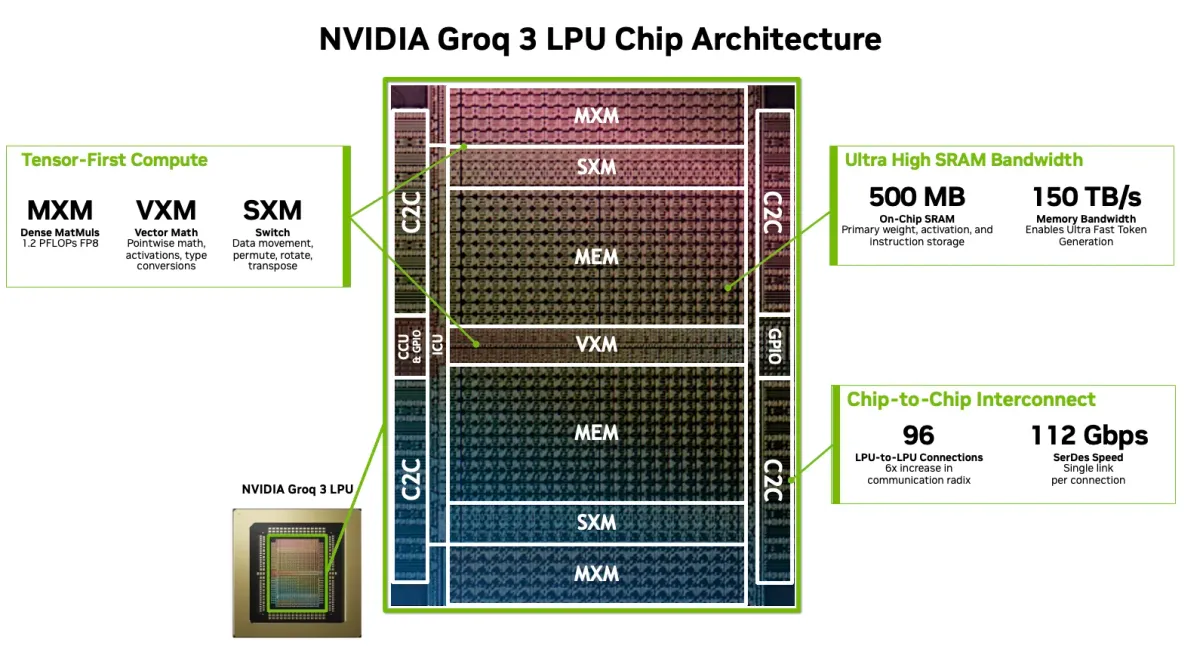
Groq 3 LPU의 핵심은 메모리 아키텍처에 있다. 기존 GPU가 HBM(고대역폭 메모리)에 의존하는 것과 달리, Groq 3는 칩 내부에 SRAM을 집적하는 방식을 택했다. 칩 하나에 500MB의 SRAM이 탑재되며, 8비트 기준 1.2 페타플롭스의 추론 성능을 제공한다.
여기서 진짜 차이가 드러나는 건 대역폭이다. Groq 3의 SRAM 대역폭은 150 TB/s. 엔비디아의 차세대 GPU인 베라 루빈에 탑재되는 HBM의 대역폭이 22 TB/s인 점을 고려하면, 약 7배에 달하는 수치다. 추론 워크로드에서 메모리 대역폭은 곧 속도다. 데이터를 얼마나 빠르게 읽고 쓸 수 있느냐가 토큰 생성 속도를 결정하기 때문이다.
"낮은 지연시간과 높은 처리량은 서로의 적이다. 그래서 우리는 둘을 위한 별도의 머신이 필요하다." — 젠슨 황, GTC 2026 키노트
256개의 LPU가 하나의 랙에 들어간다
단일 칩의 성능도 인상적이지만, Groq 3의 진가는 랙 단위에서 나타난다. Groq 3 LPX 랙은 256개의 LPU를 하나의 랙에 집적한다. 총 128GB SRAM, 40 PB/s의 내부 대역폭을 제공하는 이 시스템은 GTC 2026에서 베라 루빈 랙과 나란히 배치됐다.
| 항목 | Groq 3 LPU | 베라 루빈 GPU |
|---|---|---|
| 메모리 종류 | SRAM | HBM |
| 칩당 메모리 | 500MB | 수십 GB |
| 메모리 대역폭 | 150 TB/s | 22 TB/s |
| 최적화 대상 | 추론(낮은 지연시간) | 학습(높은 처리량) |
| 토큰/와트 효율 | GPU 대비 35배 | 기준 |
엔비디아가 자사의 최신 GPU와 LPU를 같은 무대에 올려놓은 건 의미심장하다. 학습과 추론이라는 두 가지 AI 워크로드를 단일 아키텍처로 해결하는 시대가 끝나가고 있음을 스스로 선언한 셈이다.
학습은 GPU, 추론은 LPU: 이원화의 논리
왜 GPU만으로는 안 되는 걸까. AI 학습은 방대한 데이터셋을 반복적으로 처리하며 모델의 가중치를 조정하는 작업이다. 여기서는 높은 처리량이 핵심이다. 수십 TB 규모의 파라미터를 병렬로 연산해야 하므로 대용량 HBM과 강력한 연산 유닛이 필수적이다.
반면 추론은 학습된 모델을 사용해 실시간으로 응답을 생성하는 작업이다. 챗봇이 답변을 만들거나, 코딩 에이전트가 코드를 생성하거나, 게임 내 AI NPC가 대사를 출력하는 모든 순간이 추론이다. 여기서 중요한 건 처리량이 아니라 지연시간이다. 사용자는 1초라도 빠른 응답을 원한다. 이 두 가지 요구는 근본적으로 충돌한다. 젠슨 황이 '추론 인플렉션이 도래했다'고 선언한 배경이다.
SRAM은 이 문제에 대한 하드웨어적 해답이다. HBM보다 칩에 가깝게 위치하기 때문에 접근 지연이 극적으로 낮다. 대신 용량이 작고 비용이 높다는 단점이 있지만, 추론 워크로드는 학습만큼 대용량 메모리를 필요로 하지 않는다. Groq 3가 SRAM에 올인한 건 추론이라는 특정 문제에 최적화된 설계를 선택한 결과다.
실시간 AI 서비스가 체감하게 될 변화

Groq 3 LPU의 토큰/와트 효율은 베라 루빈 GPU 대비 35배에 달한다고 엔비디아는 밝혔다. 이 수치가 실제 프로덕션 환경에서 그대로 재현될지는 지켜봐야 하지만, 방향성은 분명하다. 같은 전력으로 훨씬 더 많은 추론 요청을 처리할 수 있다는 뜻이다.
이것이 실제 서비스에 미치는 영향은 광범위하다. AI 챗봇의 응답 속도가 빨라지고, 코딩 에이전트의 코드 생성이 즉각적으로 이뤄지며, AI 기반 검색의 결과 반환 시간이 단축된다. 게이밍 영역에서는 AI NPC의 실시간 대화 생성, 게임 내 추론 기반 콘텐츠 생성, 클라우드 게이밍의 반응 속도 개선 등이 기대된다. 추론 지연이 줄어들수록 AI는 '기다리는 도구'에서 '즉각 반응하는 동반자'에 가까워진다.
엔비디아는 왜 자기 자신을 파괴하는가
흥미로운 건 엔비디아가 스스로 GPU의 한계를 인정하고 대안을 제시했다는 점이다. 그동안 엔비디아의 전략은 GPU라는 단일 아키텍처로 학습과 추론을 모두 지배하는 것이었다. 그런데 이제 추론에는 별도의 칩이 필요하다고 선언한 셈이다.
하지만 이것은 파괴가 아니라 확장이다. 추론 시장은 학습 시장보다 빠르게 성장하고 있다. AI 서비스가 확산될수록 학습은 한 번이지만 추론은 매 순간 발생한다. 엔비디아가 GPU만 고집했다면 구글, 마이크로소프트, 그록 같은 기업들이 추론 시장을 잠식했을 것이다. 200억 달러를 들여 그록을 인수한 건, 추론 시장까지 선점하겠다는 공격적 방어 전략이다.
멜라녹스 인수가 데이터센터 네트워킹이라는 빠진 퍼즐을 채웠듯, 그록 인수는 추론이라는 빠진 퍼즐을 채운다. 엔비디아는 이제 학습부터 추론까지, AI 컴퓨팅의 전체 스택을 소유한 유일한 기업이 됐다. GPU와 LPU 양날의 검을 모두 쥔 엔비디아가 AI 컴퓨팅의 새로운 질서를 어떻게 정의할지, AI 반도체 역사에서 2026년 3월은 하나의 분기점으로 기록될 가능성이 크다.



