GPT-5.4 출시 일주일, 업계 평가는?

GPT-5.4 출시 일주일, 업계 평가가 엇갈리고 있다. "OpenAI is Back"이라는 환호와 "대등 복귀일 뿐"이라는 냉정한 시선이 공존하며, Sam Altman 스스로 3가지 약점을 인정했다. 벤치마크 성과와 경쟁 구도, 한국어 성능까지 종합 정리한다.
2026년 3월 5일 GPT-5.4가 출시된 지 일주일이 지났다. 기본 모델, Thinking, Pro 세 가지 변형으로 출시된 이 모델은 네이티브 컴퓨터 사용(Computer Use), Tool Search, 100만 토큰 컨텍스트 윈도우 등 굵직한 신기능을 탑재했다. 출시 직후 업계 반응은 크게 두 갈래로 나뉘었다. Every.to가 "OpenAI is Back"이라는 헤드라인을 내걸 정도로 열광하는 쪽과, Stephen Smith처럼 "좋다, 하지만 앞서는 것은 아니다"라고 선을 긋는 쪽이 팽팽히 맞서고 있다.
일주일이 지난 지금, 초기 흥분이 가라앉고 보다 냉정한 평가가 나오기 시작했다. 벤치마크 수치, 실사용 후기, 그리고 Sam Altman 본인의 발언까지 종합해 GPT-5.4의 현주소를 짚어본다.
핵심 신기능과 벤치마크 성과
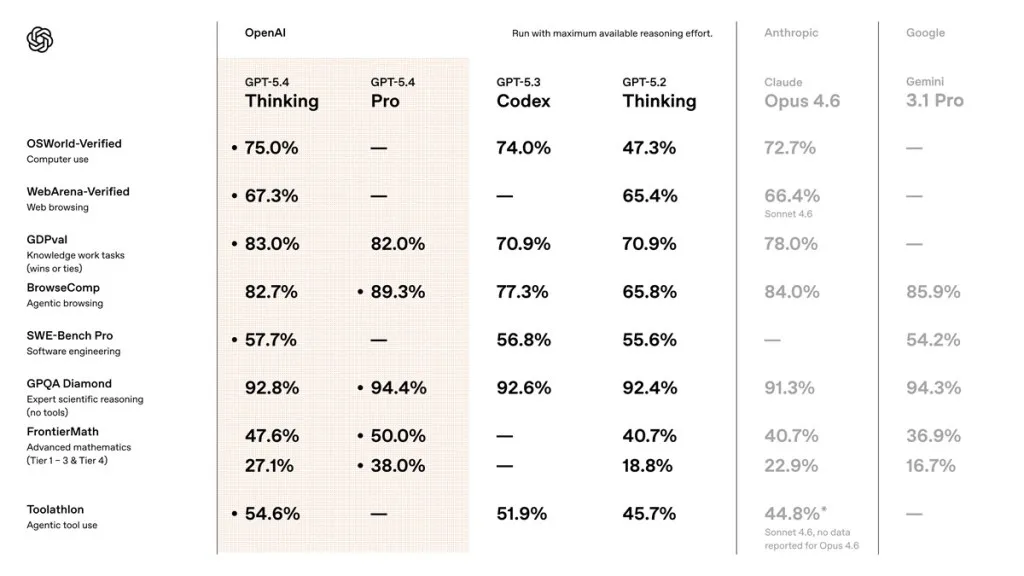
GPT-5.4의 가장 눈에 띄는 신기능은 네이티브 컴퓨터 사용이다. Playwright 기반으로 스크린샷을 읽고, 마우스와 키보드를 제어하며, 여러 애플리케이션을 넘나들며 작업을 자동화한다. OSWorld 벤치마크에서 75.0%를 기록하며 인간 기준인 72.4%를 최초로 초과했다. 데스크톱 환경에서 AI가 인간보다 정확하게 작업을 수행할 수 있음을 증명한 수치다.
두 번째 주목할 기능은 Tool Search다. 기존에는 모든 도구 정의를 프롬프트에 함께 넣어야 했지만, 이제 필요한 도구만 온디맨드로 로딩하여 토큰 사용량을 47% 절감할 수 있다. 개발자 입장에서 비용과 효율을 동시에 잡은 셈이다. 금융 플러그인도 새롭게 추가되어 엔터프라이즈 영역 확장의 신호탄을 쏘아 올렸다.
벤치마크 수치도 인상적이다. 44개 직업의 전문 업무를 측정하는 GDPval에서 83.0%, 고난이도 추론 벤치마크 ARC-AGI-2에서 73.3%(Pro 버전 83.3%)를 기록했다. 할루시네이션(환각) 오류율은 개별 33%, 전체 18% 감소했으며, 컨텍스트 윈도우는 최대 100만 토큰, 최대 출력은 128K 토큰으로 확장됐다.
"OpenAI is Back" vs "대등 복귀일 뿐": 엇갈리는 평가
긍정론의 선봉에는 AI 업계 인사들의 찬사가 있다. AI 개발자 Matt Shumer는 "세계 최고 모델, 단연코"라고 평가했고, Cloudflare는 엔지니어 1명이 $1,100의 API 비용만으로 Next.js를 1주일 만에 재구축한 사례를 공개했다. Every.to는 "GPT-5.4: OpenAI is Back"이라는 제목의 기사에서 OpenAI의 화려한 복귀를 선언했다.
반면 냉정한 시각도 만만치 않다. Stephen Smith는 "좋다. 하지만 앞서는 것은 아니다"라고 못 박았다. 일반 상식 추론에서 여전히 빈틈을 보이고, 과도한 loosening(완화) 설정 때문에 거짓말을 하거나 프롬프트를 유출하는 사례가 보고됐다. 일부 사용자는 오히려 GPT-4o 시절을 그리워하는 목소리까지 내고 있다. 한마디로, "화려한 복귀이긴 하지만 왕좌 탈환까지는 아니다"라는 것이 비판적 평가의 요지다.
Sam Altman이 인정한 3가지 약점

주목할 점은 Sam Altman 본인이 GPT-5.4의 한계를 공개적으로 인정했다는 사실이다. Altman이 꼽은 세 가지 약점은 다음과 같다.
첫째, 디자인 감각이다. UI/UX 디자인이나 시각적 결과물 생성에서 Claude와 Gemini 대비 뒤처진다는 점을 스스로 인정했다. 둘째, 실세계 맥락 이해다. 단순한 텍스트 처리를 넘어 현실 세계의 복잡한 상황을 이해하고 반영하는 능력에서 개선이 필요하다. 셋째, 복잡한 작업 완수다. 장기간에 걸친 다단계 작업을 끝까지 완수하는 능력이 아직 부족하다는 것이다.
CEO가 직접 약점을 인정하는 것은 이례적이다. 이를 투명성의 발현으로 볼 수도 있고, 경쟁이 그만큼 치열해져 더 이상 숨길 수 없게 됐다는 반증으로 읽을 수도 있다. 어느 쪽이든, OpenAI가 GPT-5.4를 완성형이 아닌 과도기적 제품으로 인식하고 있음은 분명하다.
경쟁 구도: 삼파전의 현주소
2026년 3월 AI 프론티어 모델 경쟁은 완전한 삼파전이다. Claude Opus 4.6은 SWE-bench 80.8%로 코딩 분야 부동의 1위를 지키고 있으며, 복잡한 추론과 장문 코드 생성에서 강점을 보인다. Gemini 3.1 Pro는 입력 $2, 출력 $12라는 파격적 가격에 SWE-bench 80.6%라는 준수한 성능을 겸비해 가성비 최강 모델로 자리잡았다.
GPT-5.4는 에이전트와 컴퓨터 사용에서 확실한 우위를 점했지만, 코딩에서는 Claude에, 가성비에서는 Gemini에 뒤진다. API 가격도 입력 $2.50~$5.00, 출력 $15~$20(Pro는 입력 $30, 출력 $180)으로 만만치 않다. 업계의 공통 평가는 명확하다. "GPT-5.4는 대등한 위치로 복귀했다. 하지만 앞서지는 않았다."
한국어 성능: "천지차이"의 개선
한국 시장에서 GPT-5.4의 가장 큰 화제는 한국어 성능의 대폭 개선이다. GPT-5 대비 "천지차이"라는 평가가 나올 정도로 한국어 이해와 생성 능력이 향상됐으며, 한국 수능 전 과목에서 만점을 기록했다. 이전 버전들이 한국어에서 보여준 어색함과 오역 문제가 상당 부분 해소된 것이다.
국내 업계 반응도 주목할 만하다. AI타임스는 "'AI 직원' 시대의 서막"이라며 GPT-5.4의 에이전트 기능이 기업 업무 자동화에 미칠 영향을 조명했다. 반면 NC AI의 김근교는 "예상보다 반응이 미미하다"며 소버린 AI(Sovereign AI) 기업의 필요성을 역설했다. 글로벌 AI 모델에 대한 의존도가 높아질수록 자체 AI 역량 확보가 중요해진다는 시각이다.
일주일의 결론: 복귀인가, 탈환인가
GPT-5.4 출시 일주일, 업계의 평가는 수렴하고 있다. OpenAI가 돌아왔다. 그러나 1등으로 돌아온 것은 아니다. 컴퓨터 사용과 에이전트 분야에서 인간을 넘어선 성과는 실질적이다. 하지만 코딩에서 Claude에, 추론에서 Gemini에 뒤처지며, CEO가 직접 약점을 인정해야 하는 상황은 1년 전의 OpenAI와는 확연히 다른 모습이다.
AI 프론티어 경쟁은 이제 단일 왕좌를 놓고 다투는 게임이 아니라, 각 영역에서 강점을 가진 모델들이 공존하는 다극 체제로 접어들었다. GPT-5.4는 그 체제 안에서 OpenAI의 자리를 되찾은 모델이다. 왕좌를 탈환한 모델이 아니라. 다음 차례는 GPT-5.4가 실제 업무 환경에서 얼마나 안정적으로 성능을 발휘하는지, 그리고 Altman이 인정한 약점들을 얼마나 빨리 보완하는지에 달려 있다.