제미나이 3 딥씽크, 벤치마크 1위 석권에도 냉랭한 유저들

구글 제미나이 3 딥씽크가 ARC-AGI-2, Codeforces 등 벤치마크 고점을 갱신했지만 유저 반응은 냉랭하다. 석 달간 쌓인 환각 논란 — VICE 91% 환각률, 레딧 '환각 기계' 비판 — 은 딥씽크 출시에도 가라앉지 않고 있다.
2025년 11월 18일, 구글은 제미나이 3 Pro와 Flash를 출시하며 LMArena 1위를 차지하는 등 화제를 모았다. 하지만 출시 직후부터 환각(hallucination) 문제를 중심으로 비판이 쏟아졌고, 석 달이 지난 지금까지도 불만은 가라앉지 않고 있다. 그사이 2026년 2월 12일, 구글 딥마인드는 제미나이 3 딥씽크(Deep Think)를 새롭게 선보였다. ARC-AGI-2 84.6%, Codeforces Elo 3455 등 벤치마크 고점을 갱신했지만, 유저들의 시선은 여전히 차갑다.
제미나이 딥씽크 출시, 벤치마크 고점 갱신
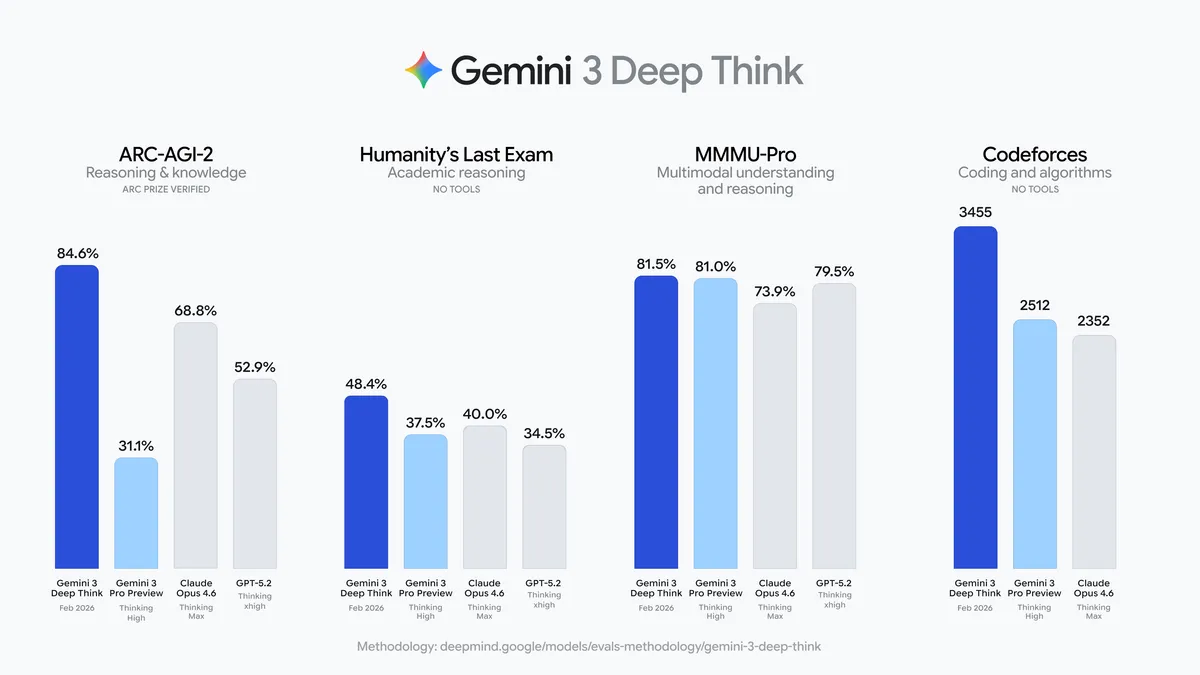
딥씽크는 제미나이 3의 특화 추론 모드로, 과학적 연구와 복잡한 문제 해결에 최적화됐다. 2월 12일 출시와 함께 수학 자동 증명 에이전트 알레테이아(Aletheia)도 소개됐는데, 에르되시 미해결 문제 13개를 해결하며 화제를 모았다. 벤치마크 성적표는 화려하다. ARC-AGI-2 84.6% 1위, HLE 48.4% 1위, Codeforces 3455 Elo 1위. IMO 81.5%, IPhO 87.7% 등 과학 올림피아드 성적도 인상적이었다.
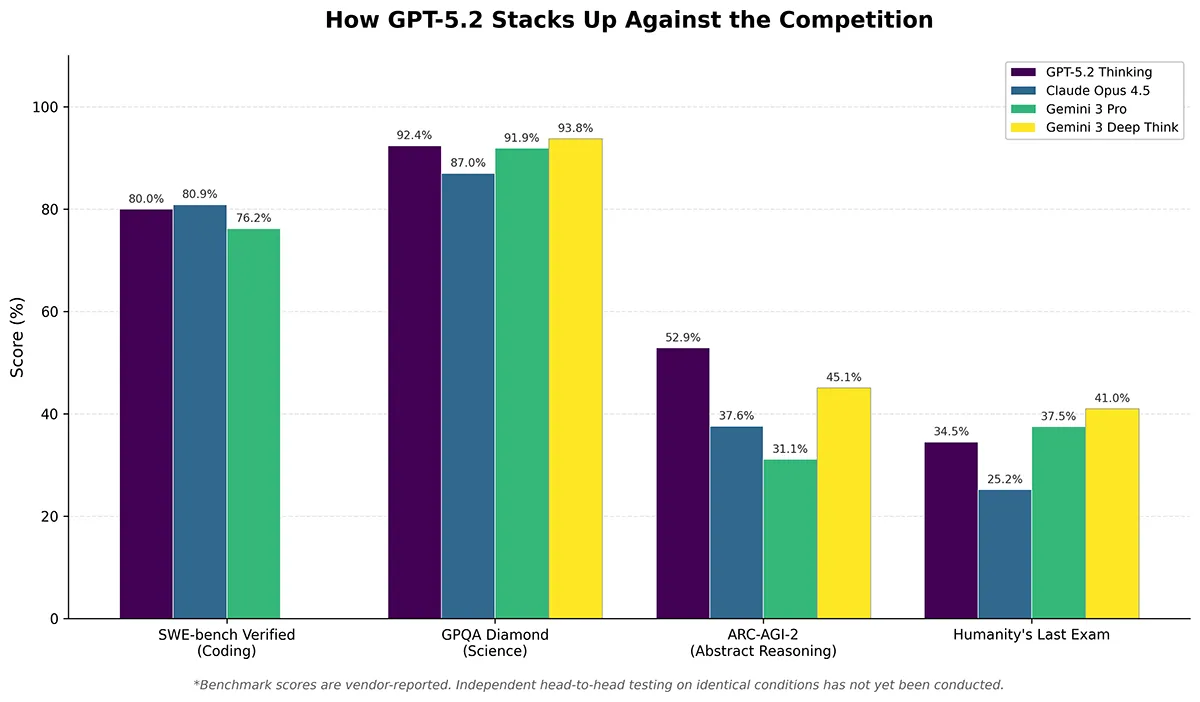
클로드 오푸스 4.6, GPT-5.2와 비교해도 과학과 추론 영역에서는 확실히 앞서는 수치다. 환각 관련 지표인 SimpleQA 72.1%, FACTS Grounding 70.5%로도 1위를 기록했다. 한편 커뮤니티에서는 딥씽크가 내부적으로 Gemini 3.1 Pro를 기반으로 한다는 추측이 퍼지고 있다. 벤치마크 DB에서 'Gemini 3.1 Pro Preview'라는 이름이 포착된 것이 계기였다. 구글은 공식 명칭을 '제미나이 3 딥씽크'로 유지하고 있다.
LessWrong 벤치마크 오염 의심, 출시 직후부터 쌓인 불신 (2025.11.20)
제미나이 3에 대한 회의론은 출시 직후부터 시작됐다. 2025년 11월 20일, LessWrong 커뮤니티에서 '평가 패러노이아(evaluation paranoia)'라는 표현이 등장했다. AI 모델의 벤치마크 점수 자체를 신뢰할 수 있느냐는 논의가 본격화된 것이다. 핵심은 벤치마크 오염(benchmark contamination) 가능성이었다. 훈련 데이터에 벤치마크 문제가 포함됐다면, 높은 점수가 진정한 추론 능력을 반영하지 않을 수 있다는 우려였다.
이는 제미나이만의 문제가 아니라 AI 업계 전반의 구조적 이슈이기도 하다. 석 달이 지난 지금, 딥씽크의 인상적인 숫자들도 이런 기존 불신의 연장선에서 봐야 한다는 것이 LessWrong의 시각이다.
Zvi의 비평, '서사 만들기'에 대한 근본적 의문 (2025.11.21)
LessWrong에서 벤치마크 오염 의심이 제기된 바로 다음 날인 11월 21일, AI 분석가 Zvi Mowshowitz도 날카로운 평가를 내놓았다. 핵심 비판은 "정확성이나 완전성을 희생하면서 서사를 만들고 있다(narrative-building at the expense of accuracy or completeness)"는 것이었다. 벤치마크 숫자로 서사를 구축하지만, 실사용 신뢰성이라는 본질적 문제는 뒷전이라는 지적이었다.
출시 이틀 만에 전문가 커뮤니티와 AI 분석가가 거의 동시에 비판의 포문을 연 셈이다. 벤치마크 숫자를 전면에 내세우지만 실사용 품질은 그에 비례하지 않는다는 지적은, 딥씽크가 발표된 지금도 유효해 보인다.
레딧과 Google Help, '환각 기계'라는 비판이 석 달째 (2025.11~2026.01)
이런 전문가 비판과 함께, 실사용자들 사이에서도 불만이 빠르게 퍼졌다. 레딧과 Google Help 포럼에서는 제미나이 3 출시 이후 석 달간 꾸준히 불만이 쌓여왔다. 대표적인 비판 포인트는 Thinking 모드의 '전화기 게임 효과(telephone game effect)'다. 긴 추론 체인을 거치면서 각 단계에서 작은 오류가 누적되고, 최종 출력이 원래 질문과 동떨어진 답변이 된다는 것이다.
"제미나이는 환각 기계(hallucination machine)"라는 직설적인 표현부터, "지시를 무시하고 자기 마음대로 답변한다", "벤치마크 1위라는데 왜 내 질문에는 엉뚱한 답을 하냐"는 의문까지 비판은 다양했다. r/Bard에서는 "제미나이 3 Pro가 형편없어서 Ultra 구독을 취소한다"는 글이 207개의 추천을 받았다. "구글이 가진 자원에 비해 제미나이가 얼마나 형편없는지 믿기 어렵다"는 반응도 꾸준히 공유됐다.
VICE 91% 환각률 보도, 쌓인 불만에 결정타 (2025.12.23)
이런 불만이 두 달 가까이 쌓여가던 중, 결정타가 날아왔다. 2025년 12월 23일, VICE는 제미나이 3 플래시(Flash) 모델을 독자적으로 테스트한 결과 91%의 환각률을 기록했다고 보고했다. 구글이 자체 벤치마크에서 발표한 수치와 극명하게 대비되는 결과였다. 테스트 방법론과 대상 모델이 다를 수 있지만, '91%'라는 숫자의 충격은 컸다.
이후 레딧과 해커뉴스에서는 "SimpleQA 1위가 무슨 의미가 있느냐"는 반응이 이어졌다. 딥씽크가 과학/수학에서 아무리 뛰어나더라도, 일반 대화에서 환각이 여전하다면 유저들의 시선이 달라지기 어렵다는 의견이 지배적이다.
딥씽크 출시 이후에도 달라지지 않는 체감 (2026.2)
그렇다면 정작 딥씽크를 써본 유저들의 반응은 어떨까. 출시 이틀밖에 지나지 않았고, AI Ultra($249.99/월) 전용이라 후기 자체가 많지 않다. 하지만 나온 반응들은 기존 불신의 연장선에 있었다. 레딧 r/Bard에서는 출시 당일 "disappointed in Deepthink"이라는 글이 올라왔다. r/GeminiAI에서는 "지난달까지 제미나이를 칭찬했는데 지금은 완전히 실망했다"는 반응이 나왔다. 한국 DC갤러리 특이점갤에서는 "논문이나 창의적 영역으로 가면 환각이나 헛소리가 심하고 논리적 비약이 꽤 많음"이라는 후기가 올라왔다.
특히 눈에 띄는 것은 '환각의 함정(The Hallucination Trap)'이라는 표현이다. r/GoogleGeminiAI에서는 "시간만 오래 걸리고 환각은 줄어들지 않는다"는 비판이 제기됐고, "클로드를 써봤더니 바로 감동받았다"는 후기도 36개의 추천을 받았다. 다모앙에서는 "할루시네이션 때문에 ChatGPT로 돌아왔다"는 반응이 나왔다. 심지어 제미나이가 Pro 플랜에서 딥씽크를 쓸 수 있다고 답했다가 스스로 환각이었다고 인정한 사례까지 공유됐다. "딥씽크가 사실은 제미나이 3.1 Pro, 결국 $250 더 받으려는 것"이라는 냉소도 퍼지고 있다.
숫자가 아닌 다른 관점에서의 개선이 필요하다
제미나이 3 딥씽크의 벤치마크 성적은 분명 인상적이다. ARC-AGI-2, HLE, Codeforces 등에서 경쟁사를 압도했고, 알레테이아를 통한 수학 연구 성과도 의미 있었다. 과학과 수학 분야에서 딥씽크가 압도적인 것은 사실이다.
하지만 석 달간 이어져온 환각 논란은 딥씽크 출시에도 가라앉지 않고 있다. LessWrong의 벤치마크 오염 의심, Zvi의 서사 비판, 레딧과 Google Help의 꾸준한 불만, VICE의 91% 환각률 보도까지. 딥씽크를 직접 써본 초기 유저들 역시 환각 문제를 지적하고 있다. 단순히 추론 성능을 높이고 벤치마크 고점을 갱신하는 것만으로는 부족하다는 것이 유저들의 메시지다. 환각 문제 해결에는 벤치마크 점수 경쟁과는 다른 관점의 접근이 필요해 보인다.


