제미나이 3.1 프로 출시, 추론과 멀티모달 모두 SOTA급 도약

구글이 제미나이 3.1 프로를 공개했다. ARC-AGI-2에서 77.1%를 기록하며 추론 능력에서 압도적 성능을 보여줬고, 할루시네이션 비율도 88%에서 50%로 대폭 줄었다. 다만 롱 컨텍스트 유지와 검색 정확도에는 여전히 과제가 남아 있다.
구글이 2월 19일 제미나이 3.1 프로(프리뷰)를 공개했다. 지난해 11월 출시된 제미나이 3 프로를 기반으로 추론, 코딩, 과학 등 거의 모든 벤치마크에서 눈에 띄는 성능 향상을 이뤄냈다. 특히 멀티모달과 추론 벤치마크인 ARC-AGI-2에서 77.1%를 기록하며 전작 대비 두 배 이상의 도약을 보여줬다.
아티피셜 애널리시스 인텔리전스 인덱스 v4.0에서도 57점으로 1위를 차지하며, 클로드 오퍼스 4.6(53점)과 GPT-5.2를 제치고 종합 성능 최상위에 올랐다. 주목할 점은 이 성능을 경쟁 모델 대비 절반 이하의 비용으로 달성했다는 것이다. 구글 AI 스튜디오, 제미나이 CLI, 버텍스 AI에서 공개 프리뷰로 사용할 수 있다.
벤치마크 성적표, 추론과 코딩에서 압도적 격차
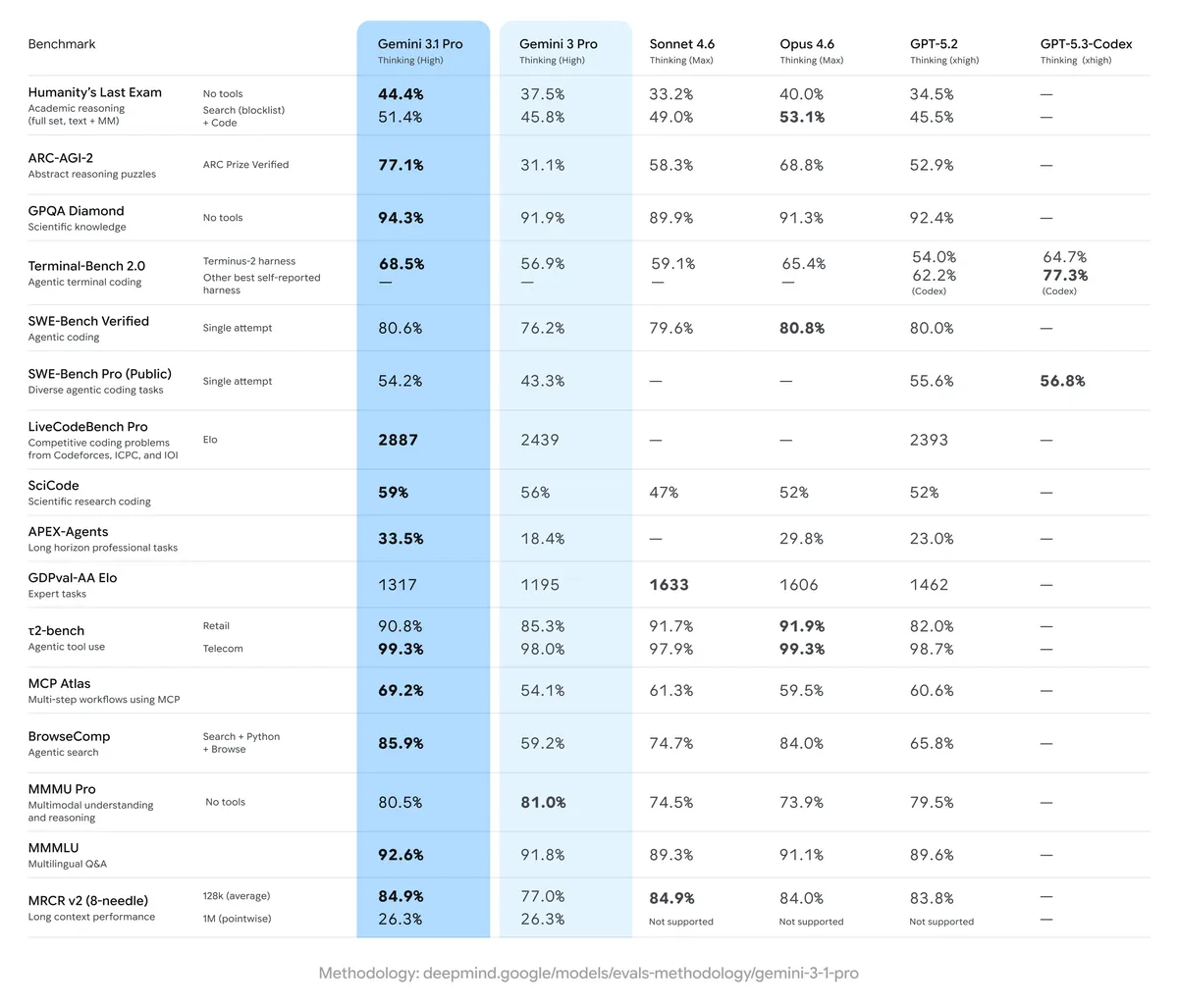
제미나이 3.1 프로의 가장 인상적인 성과는 추론 관련 벤치마크에서 나왔다. 멀티모달과 추론 능력을 측정하는 ARC-AGI-2에서 77.1%를 기록해 클로드 오퍼스 4.6(68.8%), GPT-5.2(52.9%)를 큰 폭으로 앞섰다. 인류의 마지막 시험이라 불리는 Humanity's Last Exam에서도 44.4%로 최고점을 경신했다.
코딩 영역도 마찬가지다. 라이브코드벤치 프로에서 엘로 2887을 기록해 전작(2439) 대비 450점 가까이 뛰었고, 터미널벤치 2.0에서는 68.5%로 역시 1위를 차지했다. SWE-벤치 베리파이드에서는 80.6%로 클로드 오퍼스 4.6(80.8%)과 거의 동률을 이뤘다.
과학 분야의 GPQA 다이아몬드에서도 94.3%를 기록하며 경쟁 모델들을 모두 앞섰다. 젯브레인즈는 이 모델을 두고 "15% 품질 향상, 더 강하고 빠르며 효율적"이라 평가했으며, 데이터브릭스는 자사 오피스QA 벤치마크에서 최고 성적이라고 밝혔다.
멀티모달 비전 강점과 할루시네이션 감소

제미나이 3.1 프로는 멀티모달 분야에서도 균일한 강점을 보여줬다. MMMU-Pro에서 80.5%를 기록해 GPT-5.2(79.5%), 클로드 오퍼스 4.6(73.9%)을 넘어섰다. 카트휠은 3D 변환 이해도가 대폭 향상됐다고 평가하기도 했다. 이미지와 문서 분석, 비전 기반 코딩 등에서 경쟁사 대비 우위가 뚜렷하다는 것이 커뮤니티의 전반적인 평가다.
더 주목할 부분은 할루시네이션 개선이다. AA-옴니사이언스 테스트에서 할루시네이션 비율이 88%에서 50%로 38%포인트나 줄었다. 구글은 이를 "더 많이 아는 것이 아니라 모를 때 솔직해진 것"이라 설명했다. 모르는 것을 아는 척하는 대신 모른다고 인정하는 방향으로 개선된 것이다.
브라우즈컴프(검색 능력) 벤치마크에서도 85.9%를 기록하며 클로드 오퍼스 4.6(84.0%)을 근소하게 앞질렀다. 검색과 추론을 결합한 복합 태스크에서의 능력이 전반적으로 향상된 셈이다.
여전한 과제, 롱 컨텍스트와 검색 안정성
벤치마크 성적은 화려하지만 실사용에서는 여전히 아쉬운 부분이 있다. 커뮤니티에서 가장 많이 지적되는 문제는 롱 컨텍스트 유지력이다. 공식적으로 100만 토큰 입력을 지원하지만, 30만 토큰을 넘어서면 성능이 눈에 띄게 저하된다는 피드백이 꾸준히 올라오고 있다. 긴 대화 세션에서 앞부분 맥락을 잊어버리는 현상도 보고된다. 이는 코딩 분야에서 특히 치명적인데, 대규모 코드베이스를 다루는 작업에서는 컨텍스트 메모리 유지가 핵심이기 때문이다.
코딩 도구 생태계 측면에서도 과제가 남아 있다. 벤치마크상 코딩 성능은 최상위권이지만, 실제 개발자 경험을 좌우하는 것은 모델 성능만이 아니다. 오픈AI의 코덱스나 앤트로픽의 클로드 코드처럼 이미 성숙한 코딩 전용 도구와 비교하면, 제미나이 CLI는 아직 초기 단계다. 도구의 완성도와 개발 워크플로우 통합이 뒷받침되지 않으면 벤치마크 우위가 실사용 경쟁력으로 이어지기 어렵다.
검색 기능 역시 완전하지 않다. 브라우즈컴프 벤치마크에서는 높은 점수를 받았지만, 실제 사용 시 최근 정보를 제대로 가져오지 못하는 사례가 여전히 발견된다. 딥 싱크(확장 사고) 모드 없이 사용할 때는 여전히 할루시네이션이 발생한다는 보고도 있다. 일부 사용자들은 세션 안정성 문제와 간헐적으로 "게으른" 응답을 내놓는 경향도 지적하고 있다.
SOTA 왕좌 탈환, 그러나 완성은 아직
제미나이 3.1 프로는 분명 현시점 가장 강력한 AI 모델 중 하나다. 추론, 코딩, 과학, 멀티모달 등 주요 벤치마크 10개 카테고리 중 6개에서 1위를 차지했고, 특히 추상 추론과 할루시네이션 감소에서 의미 있는 진전을 보여줬다. 가격 대비 성능까지 고려하면 경쟁력은 더욱 돋보인다.
다만 롱 컨텍스트 유지력과 검색 안정성, 세션 지속성 등 실사용 영역에서의 과제는 여전히 남아 있다. 벤치마크 1위와 실사용 체감 사이의 간극을 얼마나 빠르게 좁히느냐가 정식 출시의 관건이 될 것이다. 클로드 오퍼스 4.6, GPT-5.2와의 3파전 구도 속에서 AI 모델 경쟁이 한층 치열해졌다.



- Google Blog - Gemini 3.1 Pro: Our most capable model yet
- VentureBeat - Google launches Gemini 3.1 Pro, retaking AI crown with 2x reasoning
- Ars Technica - Google announces Gemini 3.1 Pro, says it's better at complex problem solving
- OfficeChai - Google Gemini 3.1 Pro takes top spot in Artificial Analysis Intelligence Index