제미나이 3.1 플래시 라이트, 최저가 AI의 애매한 포지션

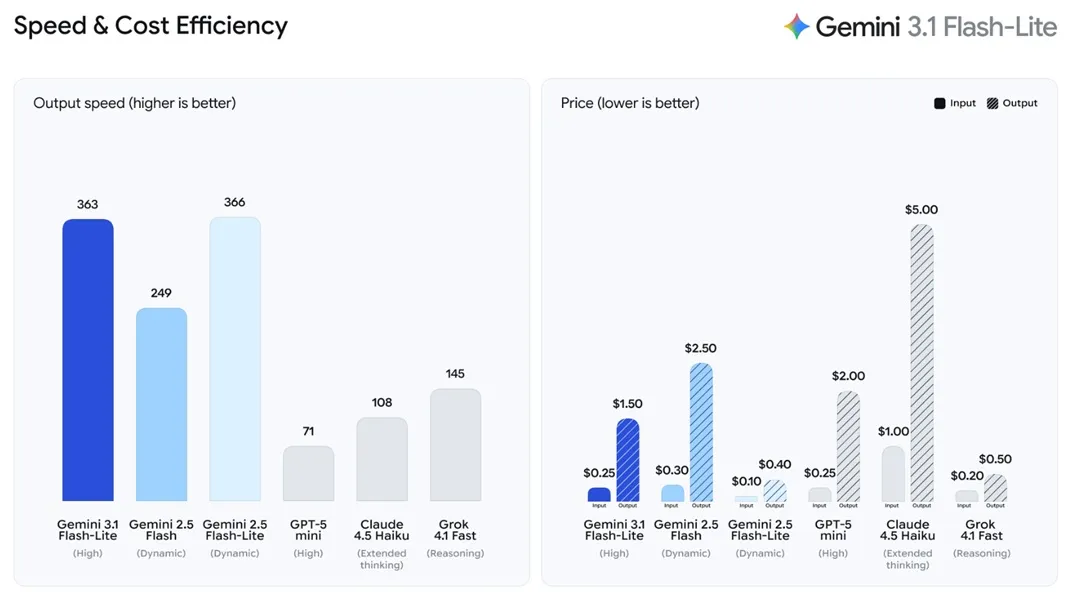
구글이 프로 모델의 8분의 1 가격을 내세운 제미나이 3.1 플래시 라이트를 출시했다. 363 토큰/초의 빠른 속도와 4단계 사고 수준 조절이 특징이지만, 전작 대비 약 3배 가격 인상으로 '최저가' 타이틀이 무색하다는 평가가 나온다.
구글이 3월 3일 제미나이 3.1 플래시 라이트(프리뷰)를 공개했다. 프로 모델의 8분의 1 가격인 입력 100만 토큰당 0.25달러, 출력 1.50달러를 내세우며 '가장 저렴한 제미나이'를 표방한다. 텍스트, 이미지, 오디오, 비디오를 모두 처리하는 멀티모달 입력에 100만 토큰 컨텍스트 윈도우까지 갖췄다.
구글 AI 스튜디오, 버텍스 AI, 제미나이 API에서 프리뷰로 이용할 수 있다. 콘텐츠 모더레이션, 번역, UI 생성, 이커머스 대량 처리 등 비용 효율이 중요한 프로덕션 환경을 겨냥한 모델이다.
가격과 속도: 프로의 8분의 1, 그러나 전작 대비 3배 인상

제미나이 3.1 플래시 라이트의 가격은 입력 100만 토큰당 0.25달러, 출력 100만 토큰당 1.50달러다. 같은 날 출시된 제미나이 3.1 프로(입력 2달러, 출력 12달러)와 비교하면 확실히 저렴하다. 속도도 인상적이다. 첫 토큰 응답 시간(TTFAT)이 2.5 플래시 대비 2.5배 빠르고, 초당 363토큰을 처리해 2.5 플래시의 249토큰/초를 크게 앞선다.
그러나 커뮤니티의 반응은 엇갈린다. 핵심 쟁점은 전작인 2.5 플래시 라이트와의 가격 비교다. 2.5 플래시 라이트는 입력 100만 토큰당 0.075달러에 불과했다. 3.1 플래시 라이트의 0.25달러는 이보다 약 3.3배 비싼 가격이다. '최저가 모델'이라는 마케팅과 달리, 실질적으로는 가격 인상이라는 지적이 나온다.
특히 대량 처리 워크로드에서 이 차이는 체감이 크다. 하루에 수백만 건의 API 호출을 돌리는 프로덕션 환경에서 3배 비용 증가는 결코 무시할 수 없는 규모다. 성능이 올랐으니 가격도 오른 것이라는 논리가 성립하지만, '플래시 라이트'라는 이름이 주는 기대와는 괴리가 있다.
Thinking Levels: 4단계 사고 수준 조절 기능
제미나이 3.1 플래시 라이트의 차별화 포인트 중 하나는 Thinking Levels 기능이다. minimal, low, medium, high 네 단계로 모델의 사고 깊이를 조절할 수 있다. 단순 분류나 키워드 추출 같은 작업에는 minimal을, 복잡한 추론이 필요한 작업에는 high를 설정하는 식이다.
이 기능은 비용 최적화와 직결된다. 모든 요청에 동일한 연산 자원을 투입하는 대신, 작업 난이도에 맞게 리소스를 분배할 수 있다. 예를 들어 콘텐츠 모더레이션처럼 빠른 판단이 필요한 작업은 minimal로 처리하고, 다국어 번역처럼 맥락 이해가 중요한 작업은 medium 이상으로 올리면 된다.
경쟁 모델들도 유사한 개념을 제공하지만, 4단계 세분화는 제미나이 플래시 라이트가 처음이다. 대량 처리 파이프라인에서 작업별로 사고 수준을 다르게 설정할 수 있다는 점은 실질적인 비용 절감 수단이 될 수 있다.
경쟁 구도: GPT-5 mini, Claude 4.5 Haiku와 비교

| 항목 | Gemini 3.1 Flash-Lite | GPT-5 mini | Claude 4.5 Haiku |
|---|---|---|---|
| Arena Elo | 1432 | - | - |
| GPQA Diamond | 86.9% | - | - |
| MMMU-Pro | 76.8% | - | - |
| MMMLU | 88.9% | - | - |
| LiveCodeBench | 72.0% | 80.4% | - |
| 컨텍스트 윈도우 | 1M 토큰 | - | 200K 토큰 |
벤치마크 성적 자체는 경량 모델치고 상당히 준수하다. GPQA 다이아몬드 86.9%, MMMU-Pro 76.8%, MMMLU 88.9%로 범용 지식과 추론 능력에서 높은 점수를 기록했다. Arena Elo 1432도 경량 모델 중에서는 최상위권이다. 100만 토큰 컨텍스트 윈도우 역시 경쟁 모델 대비 확실한 강점이다.
다만 코딩 분야에서는 약점이 드러난다. 라이브코드벤치 72.0%로 GPT-5 mini의 80.4%에 뒤처진다. 코딩 작업이 주요 유스케이스라면 가격이 다소 비싸더라도 GPT-5 mini가 나은 선택일 수 있다. Claude 4.5 Haiku 역시 코딩 특화 작업에서 강세를 보이는 모델이라 단순 가격만으로 비교하기 어렵다.
결국 '어떤 작업에 쓰느냐'가 핵심이다. 멀티모달 대량 처리나 긴 문서 분석에는 플래시 라이트의 100만 토큰 컨텍스트와 빠른 속도가 유리하고, 코딩이나 정밀 추론에는 경쟁 모델이 우위를 점한다.
마치며: 최저가의 딜레마
제미나이 3.1 플래시 라이트는 분명 기능적으로 진보한 모델이다. 363 토큰/초의 처리 속도, 4단계 Thinking Levels, 100만 토큰 컨텍스트 윈도우 등 프로덕션 환경에 필요한 스펙을 고루 갖췄다. 프로 모델 대비 8분의 1 가격이라는 포지셔닝도 매력적이다.
그러나 '최저가'라는 이름표 뒤에는 전작 대비 약 3배의 가격 인상이 숨어 있다. 성능 향상분을 감안하더라도, 이미 2.5 플래시 라이트의 가격에 맞춰 인프라를 구축한 기업들에게는 부담스러운 변화다. 코딩 벤치마크에서 GPT-5 mini에 밀리는 점도 포지션을 더 애매하게 만든다. 구글이 이 모델을 프리뷰 단계에서 정식 출시로 전환할 때, 가격 정책을 어떻게 조정할지가 시장의 주요 관심사가 될 것이다.





- Google Blog - Gemini 3.1 Flash-Lite: Our fastest, most cost-efficient model
- VentureBeat - Google releases Gemini 3.1 Flash-Lite at 1/8th the cost of Pro
- MarkTechPost - Google Drops Gemini 3.1 Flash-Lite: A Cost-Efficient Powerhouse with Adjustable Thinking Levels
- The New Stack - Google Gemini 3.1 Flash-Lite
- Artificial Analysis - Gemini 3.1 Flash-Lite Preview Analysis