같은 날 격돌, 클로드 오푸스 4.6 vs GPT 5.3 코덱스 동시 출시

2월 5일, 앤트로픽 오푸스 4.6과 오픈AI GPT 5.3 코덱스가 동시 출시됐다. 30분 간격으로 Terminal-Bench 최고 기록이 뒤바뀐 AI 코딩 에이전트 전쟁의 전말.
2026년 2월 5일, AI 업계의 양대 축인 앤트로픽과 오픈AI가 같은 날 차세대 모델을 동시에 공개했다. 앤트로픽은 오푸스 4.6을, 오픈AI는 GPT 5.3 코덱스를 내놓으며 AI 에이전트 시대의 주도권을 놓고 정면 대결 구도를 형성했다.
클로드 오푸스 4.6 — '더 오래, 더 깊이' 생각하는 범용 프리미엄
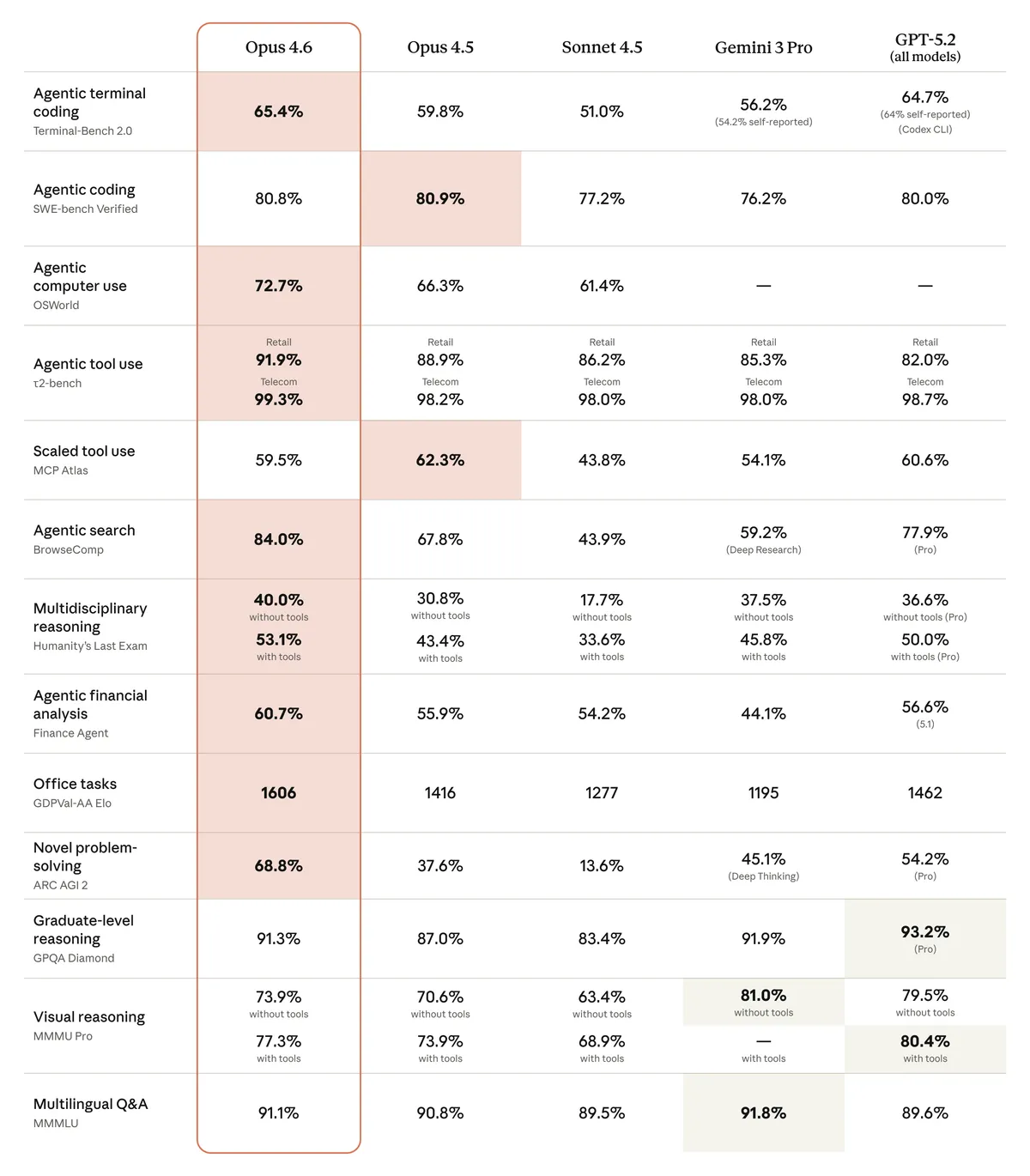

앤트로픽이 공개한 오푸스 4.6은 전작 오푸스 4.5의 코딩 능력을 전면 강화하면서도 범용 지식 업무에서 압도적 성능을 보여준다. 오푸스 계열 최초로 100만 토큰 컨텍스트(베타)를 지원하고, 최대 출력이 12만 8천 토큰으로 두 배 늘어났다.
가장 눈에 띄는 변화는 '적응형 사고' 기능이다. 기존에는 확장 사고를 켜거나 끄는 이진 선택이었지만, 이제 모델이 문맥을 파악해 깊이 사고할지 빠르게 답할지를 스스로 판단한다. 여기에 추론 레벨(최소/중간/높음/최대)을 도입해 개발자가 지능, 속도, 비용의 균형을 세밀하게 조절할 수 있게 했다.
벤치마크 성적도 인상적이다. AI 코딩 에이전트 평가인 Terminal-Bench 2.0에서 업계 최고점을 기록했고, 복합 추론 시험에서도 전 모델 중 1위를 차지했다. 실무 지식 업무 평가에서는 오픈AI의 GPT-5.2를 약 144 Elo 포인트 차이로 앞섰다. 장기 컨텍스트 검색에서는 76%를 기록하며 소넷 4.5의 18.5%를 압도했다.
클로드 코드에서는 '에이전트 팀' 기능이 프리뷰로 추가되어, 여러 에이전트가 병렬로 협업하며 코드 리뷰 같은 대규모 작업을 처리할 수 있게 됐다. 가격은 백만 토큰당 입력 5달러, 출력 25달러로 오푸스 4.5와 동일하게 유지됐다.
GPT 5.3 코덱스 — '스스로를 만든' 코딩 에이전트

같은 날 오픈AI가 내놓은 GPT 5.3 코덱스는 '자기 자신의 학습에 참여한 최초의 모델'이라는 강렬한 타이틀을 달고 등장했다. 오픈AI는 초기 버전의 GPT 5.3 코덱스가 자체 훈련을 디버깅하고, 배포를 관리하며, 테스트 결과를 진단하는 데 활용됐다고 밝혔다.
성능 면에서 GPT 5.3 코덱스는 SWE-Bench Pro(실전 소프트웨어 엔지니어링 평가)에서 56.8%로 업계 최고를 기록했고, Terminal-Bench 2.0에서는 77.3%를 달성했다. 특히 OSWorld-Verified(시각적 데스크톱 환경에서의 생산성 작업)에서 64.7%를 기록해 전작 GPT-5.2의 37.9%를 크게 뛰어넘었다.
코딩을 넘어서는 범용성도 강조됐다. 발표 자료 제작, 스프레드시트 분석, 데이터 처리 파이프라인 구축까지 지원하며, 44개 직종의 실무 지식 업무 평가에서 GPT-5.2 수준의 성능을 보여줬다. 전작 대비 25% 빨라진 속도도 주목할 점이다.
30분 뒤의 맞불 — 타이밍 전쟁
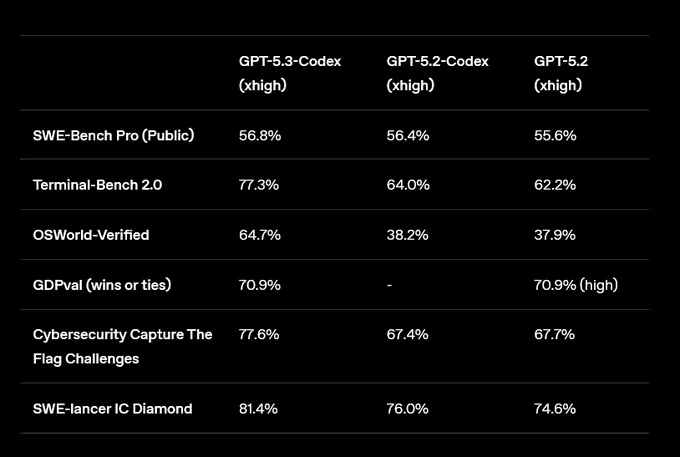
앤트로픽이 오푸스 4.6을 먼저 공개한 뒤, 오픈AI는 불과 30분 만에 GPT 5.3 코덱스를 발표하며 즉각 대응했다. 우연이라기엔 너무 정확한 타이밍이다. 업계에서는 오픈AI가 앤트로픽의 발표를 예상하고 맞불 전략을 준비한 것으로 보고 있다. 실제로 오픈AI의 코덱스 앱은 2월 2일에 이미 출시된 상태였고, 5.3-코덱스는 그 위에 올라가는 모델 업그레이드였다.
가장 극적인 장면은 Terminal-Bench 2.0 순위표에서 벌어졌다. 기존 1위는 Factory의 Droid + GPT-5.2 조합으로 64.9%였다. 오푸스 4.6은 65.4%(최대 추론)를 기록하며 0.5%p 차이로 최고 기록을 탈환했다. 하지만 불과 30분 뒤, GPT 5.3 코덱스가 77.3%를 발표하며 약 12%p 차이로 역전했다. 오푸스 4.6의 최고 기록은 30분밖에 유지되지 못한 셈이다. 다만 양사가 서로 다른 실행 환경(하네스)을 사용했기 때문에 순수 모델 성능 비교에는 한계가 있다.
벤치마크 정면 비교
양사가 공개한 수치를 직접 비교하면 다음과 같다. Terminal-Bench 2.0: 오푸스 4.6 65.4% 대 GPT 5.3 코덱스 77.3%. SWE-Bench에서는 흥미롭게도 양사가 서로 다른 평가 버전을 선택했다. 앤트로픽은 검증판(80.84%)과 다국어판(77.83%)을 발표한 반면, 오픈AI는 프로판(56.8%)을 내세웠다. 현재 SWE-Bench 프로판 순위표에는 전작 오푸스 4.5가 45.89%로 1위를 차지하고 있어, 오푸스 4.6의 프로판 점수가 공개되면 판도가 뒤바뀔 가능성도 있다. 양사 모두 자사에 유리한 평가 기준을 전면에 내세운 셈이다.
실무 지식 업무 평가에서는 오푸스 4.6이 GPT-5.2를 약 144 Elo 포인트 차이로 앞섰다. GPT 5.3 코덱스는 같은 평가에서 70.9% 승률을 기록해 GPT-5.2 수준을 유지했다. 데스크톱 환경 생산성 작업 평가에서는 GPT 5.3 코덱스가 64.7%로 압도적이었다. 사이버보안 해킹 대회 평가에서는 GPT 5.3 코덱스가 77.6%를 기록한 반면, 오푸스 4.6은 정확한 수치 대신 '업계 최고'라는 표현을 사용했다.
장기 컨텍스트에서는 오푸스 4.6이 확실한 우위를 점했다. 100만 토큰 규모의 문서에서 핵심 정보를 찾아내는 평가에서 76%를 기록해 소넷 4.5의 18.5%를 압도했다. 오푸스 4.6은 100만 토큰 컨텍스트(베타)와 12만 8천 출력 토큰을 지원하는 반면, GPT 5.3 코덱스는 컨텍스트 압축을 통해 긴 세션을 관리하는 방식을 택했다.
AI 에이전트 전쟁은 이제 시작이다
공교롭게도 이번 동시 출시는 슈퍼볼 광고를 둘러싼 양사의 설전 직후에 벌어졌다. 전날까지 SNS에서 언쟁을 주고받던 두 회사가 다음 날 같은 시각에 차세대 모델을 내놓은 셈이다. 양사의 치열한 경쟁은 앞으로도 AI 업계 최대의 관전 포인트가 될 것이다.
한편 GPT 5.3 코덱스가 GPT-5.2 기반 모델이라고 명시된 점은 의아하다. '5.3'이라는 넘버링에 비해 아키텍처 변화보다는 코딩 에이전트 특화 튜닝에 가까운 것 아니냐는 해석이 나온다.

