딥시크 V4 출격 대기: 3월 4일 출시 유력

딥시크가 3월 4일 중국 양회 개막에 맞춰 차세대 모델 V4를 공개할 것으로 관측된다. 1조 파라미터 MoE 아키텍처, 100만 토큰 컨텍스트, Engram 메모리 기술 등 파격적 스펙과 함께 GPT-5.2 대비 1/6 수준인 가격 경쟁력이 AI 업계 판도를 흔들 전망이다.
3월 4일 양회 개막, V4 출시 카운트다운
중국 AI 스타트업 딥시크(DeepSeek)가 3월 4일 차세대 대형언어모델 V4를 공개할 것으로 관측된다. 이 날짜는 중국 최대 정치 행사인 전국인민대표대회(양회) 개막일과 정확히 맞물린다. 딥시크는 올해 초 V3 후속 모델 출시를 여러 차례 예고했으나 수차례 연기를 거듭했고, 이번에야 비로소 확정적인 출시 시그널이 포착되고 있다.
복수의 업계 관계자와 외신에 따르면, 딥시크는 이번 주 내로 V4 모델을 발표할 예정이며, 양회 기간 중 발표라는 점에서 중국 정부의 AI 기술 자립 의지를 대외적으로 과시하려는 전략적 타이밍으로 해석된다. TechNode는 딥시크 내부 소식통을 인용해 "이번 주 출시가 확실하다"고 보도했고, PYMNTS 역시 "발표 임박" 기조를 전했다.
딥시크는 2024년 12월 V3를 출시하며 오픈소스 AI 시장에 돌풍을 일으켰고, 2025년 1월 추론 특화 모델 R1으로 글로벌 AI 업계에 충격을 안겼다. V4는 그 후속작으로서, 텍스트를 넘어 이미지와 영상까지 아우르는 네이티브 멀티모달 모델로의 도약이 예고되어 있다.
파격 스펙: 1T MoE와 100만 토큰 컨텍스트
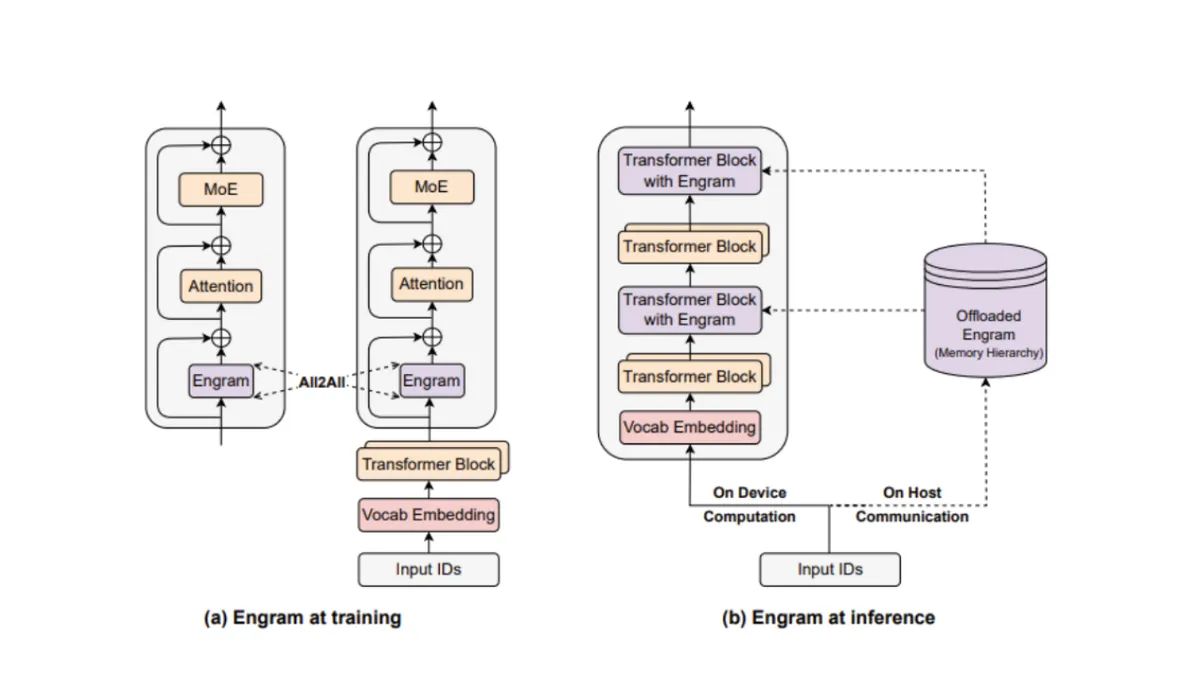
V4의 가장 눈에 띄는 변화는 아키텍처의 대폭 확장이다. 총 파라미터 수는 약 1조(1T)에 달하는 Mixture-of-Experts(MoE) 구조를 채택하면서도, 실제 추론 시 활성화되는 파라미터는 약 320억(32B)으로 유지해 효율성과 성능을 동시에 잡는다는 전략이다. 이는 V3의 6,710억 파라미터(활성 370억)에서 총 규모는 크게 키우면서 활성 파라미터는 오히려 줄인 설계로, 연산 효율을 극대화하려는 의도가 읽힌다.
컨텍스트 윈도우는 100만 토큰으로 확대되었다. GPT-4o의 12.8만 토큰, Claude 3.5 Sonnet의 20만 토큰과 비교하면 압도적인 수치다. 이를 가능하게 하는 핵심 기술이 바로 Engram Conditional Memory다. 기존 트랜스포머가 긴 문맥을 처리할 때 O(n) 이상의 연산 복잡도를 보이는 것과 달리, Engram은 O(1) 조회 시간으로 과거 맥락에 접근할 수 있는 인간 뇌의 장기 기억 메커니즘에서 영감을 받은 기술이다.
Tom's Hardware에 따르면, Engram은 학습과 추론 단계 모두에 내장되며 "가중치 기반 영구 기억"을 형성한다. 이는 단순히 긴 텍스트를 읽는 것을 넘어, 과거 세션의 맥락까지 효율적으로 활용할 수 있음을 의미한다. 또한 Manifold-Constrained Hyper-Connections 기술로 레이어 간 정보 흐름을 최적화해 기존 잔차 연결(residual connection)의 한계를 넘어섰다.
멀티모달 역시 V4의 핵심 차별점이다. V3가 텍스트 전용이었던 것과 달리, V4는 텍스트, 이미지, 영상을 네이티브로 처리하는 통합 멀티모달 모델로 설계되었다. 이는 GPT-4o, Gemini 2.0과 직접 경쟁하겠다는 의지의 표현이다.
가격 파괴: 경쟁사의 1/4 수준
딥시크의 가장 강력한 무기는 단연 가격이다. V4의 예상 인풋 토큰 가격은 100만 토큰당 약 $0.28 수준으로, 이는 경쟁 모델 대비 파격적인 수치다.
| 모델 | 인풋 가격 | 비고 |
|---|---|---|
| DeepSeek V4 (예상) | ~$0.28 | MoE 1T / 활성 32B |
| GPT-5.2 (OpenAI) | $1.75 | 최신 프론티어 |
| Claude Opus 4.6 (Anthropic) | $5.00 | 표준 200K 컨텍스트 기준 |
| Gemini 3.1 Pro (Google) | $2.00 | 200K 이하 컨텍스트 기준 |
| DeepSeek V3 (현행) | ~$0.27 | MoE 671B / 활성 37B |
V4의 가격은 V3와 거의 동일한 수준을 유지하면서 성능은 대폭 향상시킨 것으로 보인다. GPT-5.2 대비 약 1/6, Claude Opus 4.6 대비 약 1/18, Gemini 3.1 Pro 대비 약 1/7 수준이다. 이러한 가격 경쟁력은 딥시크가 중국 내 저렴한 인건비와 효율적인 MoE 아키텍처를 통해 달성한 것으로 분석된다. 특히 오픈소스 정책을 유지할 경우, API뿐 아니라 자체 배포를 원하는 기업들에게도 매력적인 선택지가 된다.
블랙웰 칩 논란: 기술 자립인가, 수출통제 위반인가

V4 출시를 앞두고 가장 논쟁적인 이슈는 학습에 사용된 칩이다. 딥시크 측은 화웨이의 Ascend 910B와 캠브리콘 칩을 중심으로 학습을 진행했다고 주장하며, 이를 중국 AI의 기술 자립 사례로 내세우고 있다. 그러나 미국 측에서는 전혀 다른 시각이 나온다.
다수의 외신과 업계 분석가들은 딥시크가 엔비디아의 최신 블랙웰(Blackwell) B200 칩을 대량 확보해 학습에 활용했을 가능성을 제기하고 있다. 미국 정부의 대중국 첨단 반도체 수출통제에도 불구하고 우회 경로를 통해 입수했다는 의혹이다. 관련 보도에 따르면, 딥시크가 보유한 GPU 수량이 공식적으로 확인된 것보다 상당히 많다는 정황이 포착되고 있다.
이 논란은 단순한 기업 차원을 넘어 미-중 기술 패권 경쟁의 핵심 쟁점으로 부상했다. 만약 수출통제 위반이 확인될 경우, 딥시크에 대한 제재는 물론 중국 AI 생태계 전체에 파급 효과가 미칠 수 있다. 반대로 화웨이 칩만으로 V4급 모델을 학습시킨 것이 사실이라면, 중국의 반도체 자립이 예상보다 빠르게 진행되고 있음을 의미한다.
마치며: AI 패권 경쟁의 새로운 국면
딥시크 V4의 등장은 AI 업계의 경쟁 구도를 근본적으로 뒤흔들 잠재력을 지닌다. 1조 파라미터 규모에 100만 토큰 컨텍스트, 그리고 경쟁사 대비 파격적인 가격까지, V4가 공개된 벤치마크에서 예고된 성능을 실제로 입증한다면, OpenAI와 Google, Anthropic에게는 상당한 압박이 될 수밖에 없다.
특히 양회 기간 발표라는 점은 이 모델이 단순한 기술 제품을 넘어 중국의 AI 역량을 상징하는 정치적 메시지이기도 하다는 것을 시사한다. 블랙웰 칩 논란의 결말에 따라 미국의 수출통제 정책이 더욱 강화될 수도, 혹은 중국의 기술 자립 내러티브가 힘을 얻을 수도 있다.
3월 4일, 딥시크의 발표가 AI 패권 경쟁의 다음 장을 어떻게 쓸지 전 세계가 주목하고 있다.


